
CAP 理论:分布式系统的三选二原则与 Java 实战
还记得那次生产环境的数据库突然宕机吗?整个团队手忙脚乱,老板不停打电话催进度,用户投诉电话打爆客服。那一刻,我们多希望系统能持续可用啊!但现实是,为了保证数据一致性,我们不得不让系统暂时下线。这就是分布式系统中最经典的矛盾 —— CAP 理论下的抉择。无论是构建微服务架构,还是设计分布式数据库,这个问题都绕不开。今天,我们一起深入理解 CAP 理论,看看为什么它不可能三者兼得,以及在 Java 中如何应对这个挑战。
CAP 理论基础
CAP 理论是分布式系统设计的基础理论,由 Eric Brewer 教授在 2000 年提出。它指出分布式系统无法同时满足以下三个特性:
一致性(Consistency): 所有节点在同一时间看到的数据是一致的
可用性(Availability): 系统保证每个请求都能得到响应
分区容错性(Partition Tolerance): 系统在网络分区故障时仍能正常运行
这里有个关键点:在分布式环境下,网络分区是一个必然存在的问题,因此 P 不是可选项而是必须处理的现实。CAP 理论真正的含义是:在存在网络分区的情况下,系统无法同时满足一致性和可用性。
简单来说,当网络出问题时,你只能选择:要么保证数据一致但部分服务不可用,要么保证服务可用但数据可能不一致。
为什么不能三者兼得?
我用一个简单的例子来说明:
想象你有两个数据节点 A 和 B,它们之间的网络突然断开:
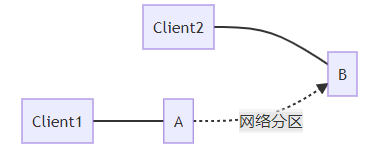
此时,Client1 向节点 A 写入数据 X=1,但由于网络问题,节点 B 无法得知这一更新。
现在,Client2 向节点 B 查询 X 的值,我们有两个选择:
拒绝 Client2 的请求(保证 C,牺牲 A):"对不起,我无法确认最新值,请稍后再试"
返回旧值(保证 A,牺牲 C):"根据我所知,X 的值是 0"
无论选哪个,都不可能同时满足 C 和 A。这就像物理定律一样,不可违背。
Java 代码演示 CAP 问题
我们通过一个简化的 Java 代码示例来直观演示 CP 和 AP 两种选择:
public class CAPSimpleDemo {
// 模拟分布式系统的节点
static class Node {
private String name;
private Map<String, String> data = new ConcurrentHashMap<>();
private boolean canReachPeer = true; // 是否能与对等节点通信
public Node(String name) {
this.name = name;
}
// 模拟网络分区
public void disconnectFromPeer() {
canReachPeer = false;
System.out.println(name + "与对等节点的网络连接断开");
}
public void reconnectToPeer() {
canReachPeer = true;
System.out.println(name + "与对等节点的网络连接恢复");
}
// CP模式:强一致性,可能牺牲可用性
public void writeCP(Node peer, String key, String value) {
if (!canReachPeer) {
System.out.println(name + ": CP写入失败 - 无法与对等节点通信,拒绝写入");
throw new RuntimeException("无法保证一致性,拒绝写入");
}
// 两阶段提交:第一阶段 - 准备
peer.data.put(key + "_prepare", value);
data.put(key + "_prepare", value);
// 两阶段提交:第二阶段 - 提交
peer.data.put(key, value);
data.put(key, value);
System.out.println(name + ": CP写入成功: " + key + "=" + value);
}
// AP模式:高可用性,牺牲一致性
public void writeAP(Node peer, String key, String value) {
// 本地写入总是成功
data.put(key, value);
System.out.println(name + ": AP本地写入成功: " + key + "=" + value);
// 尝试同步到对等节点,但不阻塞操作
if (canReachPeer) {
peer.data.put(key, value);
System.out.println(name + ": 数据已同步到" + peer.name);
} else {
System.out.println(name + ": 无法同步到" + peer.name + ",数据将暂时不一致");
// 在真实系统中,这里会将数据放入本地队列,等网络恢复后再同步
}
}
public String read(String key) {
String value = data.getOrDefault(key, "未找到数据");
System.out.println(name + ": 读取 " + key + "=" + value);
return value;
}
}
public static void main(String[] args) {
// 创建两个节点
Node nodeA = new Node("节点A");
Node nodeB = new Node("节点B");
// 正常情况下(无网络分区)
System.out.println("=== 正常网络环境 ===");
nodeA.writeCP(nodeB, "user", "张三");
System.out.println("节点A读取: " + nodeA.read("user"));
System.out.println("节点B读取: " + nodeB.read("user"));
// 模拟网络分区
System.out.println("\n=== 发生网络分区 ===");
nodeA.disconnectFromPeer();
nodeB.disconnectFromPeer();
// CP模式下的网络分区
System.out.println("\n=== CP模式下尝试写入 ===");
try {
nodeA.writeCP(nodeB, "user", "李四");
} catch (Exception e) {
System.out.println("异常: " + e.getMessage());
}
// AP模式下的网络分区
System.out.println("\n=== AP模式下尝试写入 ===");
nodeA.writeAP(nodeB, "user", "李四");
// 查看数据不一致
System.out.println("\n=== 检查数据一致性 ===");
System.out.println("节点A读取: " + nodeA.read("user"));
System.out.println("节点B读取: " + nodeB.read("user"));
// 恢复网络
System.out.println("\n=== 网络恢复 ===");
nodeA.reconnectToPeer();
nodeB.reconnectToPeer();
// 在真实系统中,这里会有数据同步机制
System.out.println("\n注意:真实系统中,网络恢复后AP系统会通过同步机制实现最终一致性");
}
}这个简化示例清晰展示了关键区别:
CP 模式在网络分区时拒绝写入,保证数据一致性
AP 模式允许本地写入,但导致暂时的数据不一致
一致性模型详解
在分布式系统中,一致性不是非黑即白的,而是有多种级别:
最终一致性并非"数据永远可能不一致",而是保证在没有新更新的情况下,经过一段时间后所有副本最终会收敛到相同状态。
系统选型:CP 还是 AP?
不同类型的系统在 CAP 光谱上有不同定位:
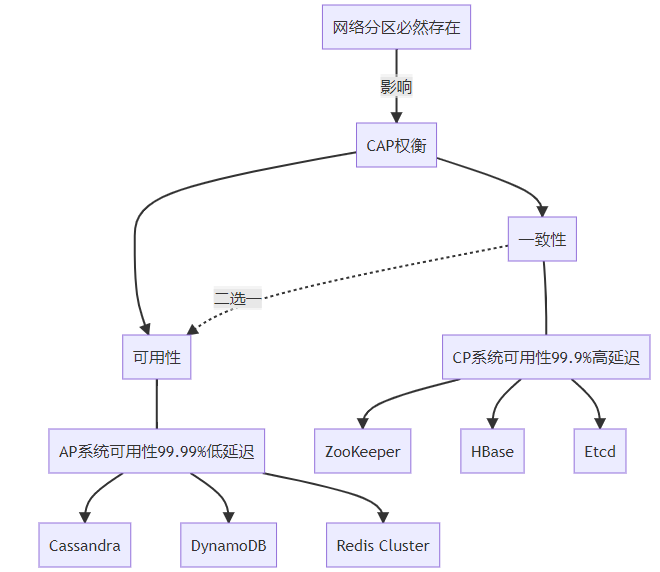
CP 系统:ZooKeeper 分布式锁
ZooKeeper 通过临时有序节点实现分布式锁,保证强一致性:
public class ZKDistributedLock {
private final ZooKeeper zk;
private final String lockPath;
private String myLockNode;
public ZKDistributedLock(ZooKeeper zk, String lockPath) {
this.zk = zk;
this.lockPath = lockPath;
// 确保锁路径存在
try {
if (zk.exists(lockPath, false) == null) {
zk.create(lockPath, new byte[0],
ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT);
}
} catch (Exception e) {
throw new RuntimeException("创建锁路径失败", e);
}
}
public boolean tryLock() throws Exception {
// 创建临时有序节点
myLockNode = zk.create(lockPath + "/lock-", new byte[0],
ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL_SEQUENTIAL);
// 获取所有锁节点并排序
List<String> children = zk.getChildren(lockPath, false);
Collections.sort(children);
// 获取序号最小的节点
String lowestNode = children.get(0);
String myNode = myLockNode.substring(myLockNode.lastIndexOf('/') + 1);
// 如果我们的节点是最小的,则获得锁
if (myNode.equals(lowestNode)) {
return true;
}
// 否则锁已被他人占用
return false;
}
public void unlock() throws Exception {
if (myLockNode != null) {
zk.delete(myLockNode, -1);
myLockNode = null;
}
}
}当网络分区发生时,ZooKeeper 集群无法达成多数派选举,会停止接受写入,保证数据一致性而牺牲可用性。
AP 系统:Cassandra 的一致性级别
Cassandra 允许调整一致性级别,平衡可用性和一致性:
import com.datastax.oss.driver.api.core.CqlSession;
import com.datastax.oss.driver.api.core.cql.*;
public class CassandraConsistencyDemo {
public static void main(String[] args) {
try (CqlSession session = CqlSession.builder()
.addContactPoint(new InetSocketAddress("127.0.0.1", 9042))
.withLocalDatacenter("datacenter1")
.withKeyspace("example")
.build()) {
UUID sensorId = UUID.randomUUID();
// 高可用性写入 (LOCAL_ONE)
System.out.println("执行高可用性写入...");
session.execute(
SimpleStatement.builder(
"INSERT INTO sensors (id, location, temperature) VALUES (?, ?, ?)")
.addPositionalValues(sensorId, "机房A", 23.5)
.setConsistencyLevel(DefaultConsistencyLevel.LOCAL_ONE)
.build());
// 强一致性读取 (QUORUM)
System.out.println("执行强一致性读取...");
ResultSet rs = session.execute(
SimpleStatement.builder("SELECT * FROM sensors WHERE id = ?")
.addPositionalValue(sensorId)
.setConsistencyLevel(DefaultConsistencyLevel.QUORUM)
.build());
Row row = rs.one();
if (row != null) {
System.out.println("读取温度: " + row.getDouble("temperature") + "°C");
}
System.out.println("当网络分区发生时:");
System.out.println("- LOCAL_ONE: 只要本地一个节点可用就能成功,高可用但可能不一致");
System.out.println("- QUORUM: 需要大多数节点响应,一致性高但可用性较低");
}
}
}Cassandra 提供多种一致性级别,在 CAP 光谱上灵活移动:
ONE/LOCAL_ONE:只需一个节点确认,高可用但一致性弱QUORUM/LOCAL_QUORUM:需要多数节点确认,平衡一致性和可用性ALL:所有节点确认,强一致性但低可用性
同时,Cassandra 通过多种机制实现最终一致性:
读修复:读取时发现不一致会修复
提示移交:节点不可用时先存在其他节点,恢复后再同步
反熵过程:后台定期同步节点数据
分布式事务与 CAP
分布式事务跨多个服务协调数据变更,同样面临 CAP 抉择。以下是使用 Seata 框架的示例:
@Service
public class OrderService {
@Autowired
private JdbcTemplate jdbcTemplate;
@Autowired
private RestTemplate restTemplate;
/**
* AT模式的全局事务
* 需先部署Seata Server (TC/事务协调器)
* 本服务充当TM(事务管理器)
* 数据库作为RM(资源管理器)
*/
@GlobalTransactional(timeoutMills = 10000)
public void createOrder(String userId, String productId, int quantity) {
// 1.创建订单(本地事务)
jdbcTemplate.update(
"INSERT INTO orders (user_id, product_id, quantity) VALUES (?, ?, ?)",
userId, productId, quantity
);
// 2.调用库存服务扣减库存(远程事务)
boolean result = restTemplate.getForObject(
"http://inventory-service/inventory/deduct?productId={1}&quantity={2}",
Boolean.class,
productId,
quantity
);
if (!result) {
throw new RuntimeException("库存不足");
}
// 3.调用用户服务扣减积分(远程事务)
restTemplate.getForObject(
"http://user-service/user/deduct-points?userId={1}&points={2}",
Void.class,
userId,
10 // 下单奖励积分
);
}
}Seata 的工作原理:
全局事务开始:创建 XID(全局事务 ID)
分支事务执行:
在本地事务提交前,记录修改前数据(undo_log)
正常提交本地事务
全局提交/回滚:协调器通知各分支提交或根据 undo_log 回滚
在网络分区时,Seata 倾向于一致性(CP),可能导致事务长时间等待。
Seata 模式对比
BASE 理论:缓解 CAP 约束
BASE 理论是对 CAP 理论的补充,特别适用于 AP 系统:
基本可用(Basically Available): 允许降级服务
软状态(Soft State): 允许中间状态
最终一致性(Eventually Consistent): 数据最终达到一致
BASE 是 AP 系统在分区恢复后向 CP 收敛的方法论,就像弹簧,被拉开后最终会回到平衡状态。
案例分析:实时监控告警系统
监控系统需要从各服务器收集指标并触发告警,面临 CAP 抉择:
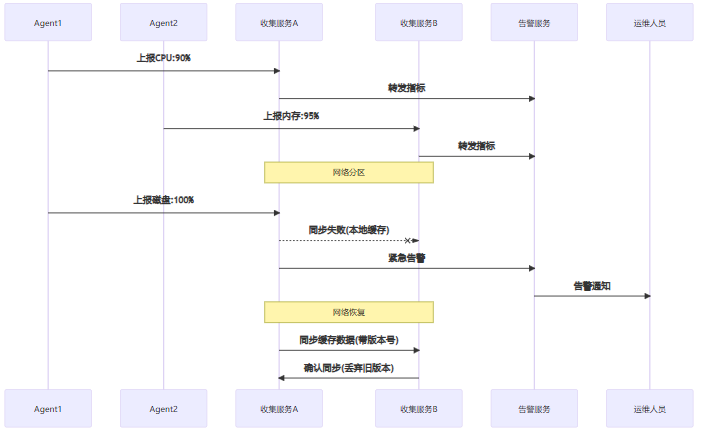
实现告警服务的核心代码:
@Service
public class AlertService {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
// 本地缓存,存储待同步的告警
private final ConcurrentMap<String, Alert> pendingAlerts = new ConcurrentHashMap<>();
/**
* 处理紧急告警 - AP模式优先
*/
public void handleCriticalAlert(Alert alert) {
// 生成幂等ID
String alertId = alert.getSource() + "-" + alert.getTimestamp();
try {
// 直接发送告警,确保可用性
sendAlert(alert);
// 异步记录告警历史
CompletableFuture.runAsync(() -> {
try {
// 带版本号写入Kafka,确保最终一致性
kafkaTemplate.send("alert-history",
objectMapper.writeValueAsString(alert));
} catch (Exception e) {
// 发生异常,放入本地缓存等待重试
pendingAlerts.put(alertId, alert);
log.error("记录告警历史失败: {}", e.getMessage());
}
});
} catch (Exception e) {
// 主要渠道失败,使用备用渠道
sendAlertViaBackupChannel(alert);
}
}
/**
* 网络恢复后的数据同步
*/
@Scheduled(fixedRate = 60000) // 每分钟执行
public void syncPendingAlerts() {
if (!pendingAlerts.isEmpty()) {
Iterator<Map.Entry<String, Alert>> it = pendingAlerts.entrySet().iterator();
while (it.hasNext()) {
Map.Entry<String, Alert> entry = it.next();
Alert alert = entry.getValue();
try {
// 重新写入Kafka
kafkaTemplate.send("alert-history",
objectMapper.writeValueAsString(alert));
// 同步成功,从缓存移除
it.remove();
} catch (Exception e) {
// 继续失败,下次重试
}
}
}
}
}这个例子展示了典型的 AP 系统设计:
优先确保告警发送(高可用性)
使用本地缓存存储失败的操作
网络恢复后通过定时任务同步,实现最终一致性
使用版本号或时间戳解决冲突
业务场景决策矩阵
常见误区
理解 CAP 理论时的常见误区:
最终一致性不等于弱一致性:最终一致性保证数据最终收敛,而弱一致性没有收敛保证。
CA 系统在分布式环境不存在:分布式系统必须处理网络分区,因此只有单机系统才能是 CA。
过度追求强一致性:许多场景(如社交点赞)用户更关心可用性,不需要强一致性。
忽略延迟因素:CP 系统通常延迟更高,可能影响用户体验。
系统对比案例
Redis 集群和 ZooKeeper 展示了两种不同方向:
Redis 优先保证可用性,在分区时继续提供服务
ZooKeeper 优先保证一致性,在分区时少数派停止写入